

TIP此筆記僅為個人在 Google Cloud Summit 2024 活動中所記錄的內容,可能存在主觀理解或資訊缺漏。內容僅供參考,不代表官方立場或觀點。
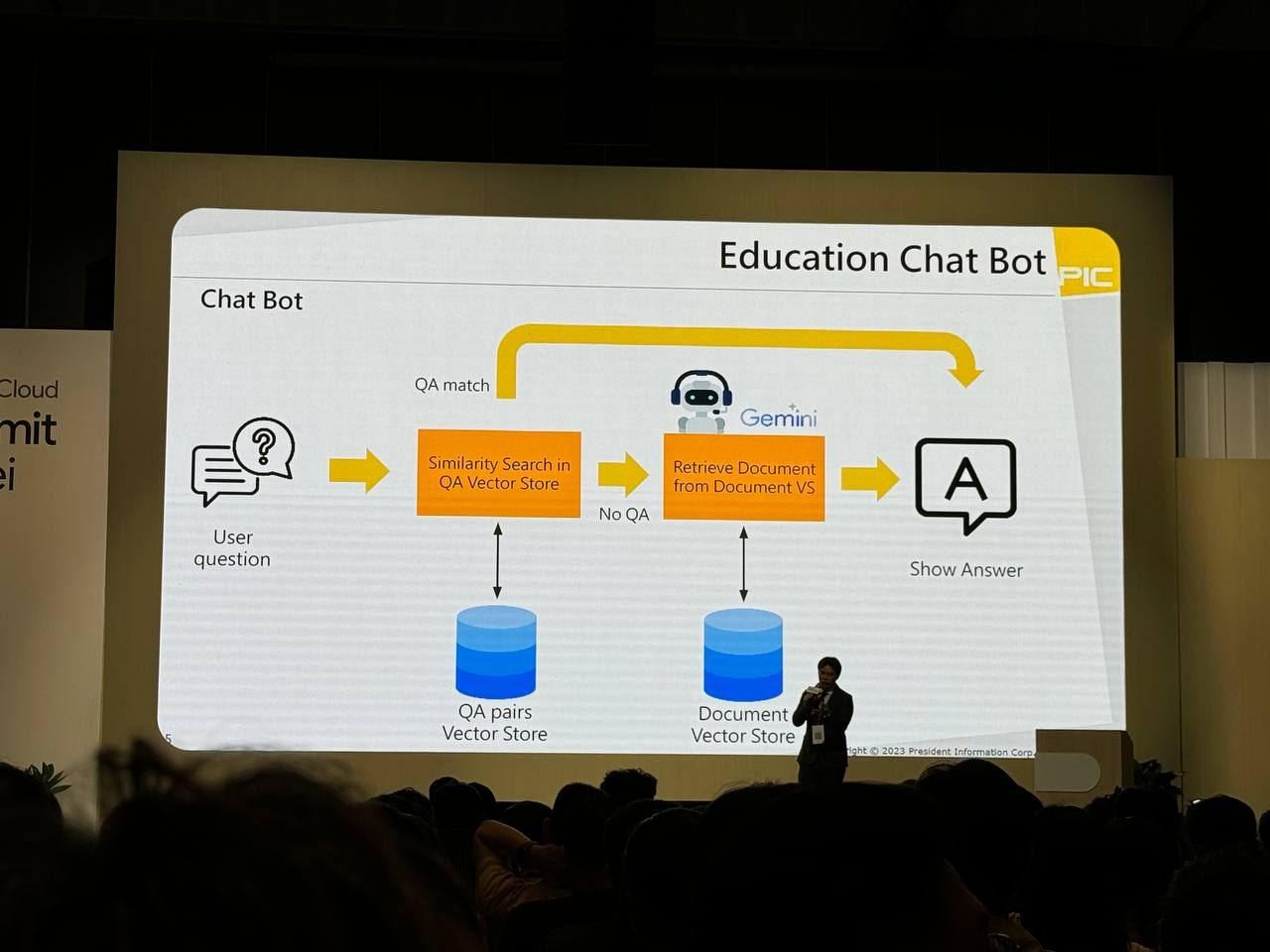
Chat bot
教育聊天機器人如何透過問答匹配、相似度搜索和文件檢索等技術,從知識庫中提取資訊來回答使用者問題的過程。
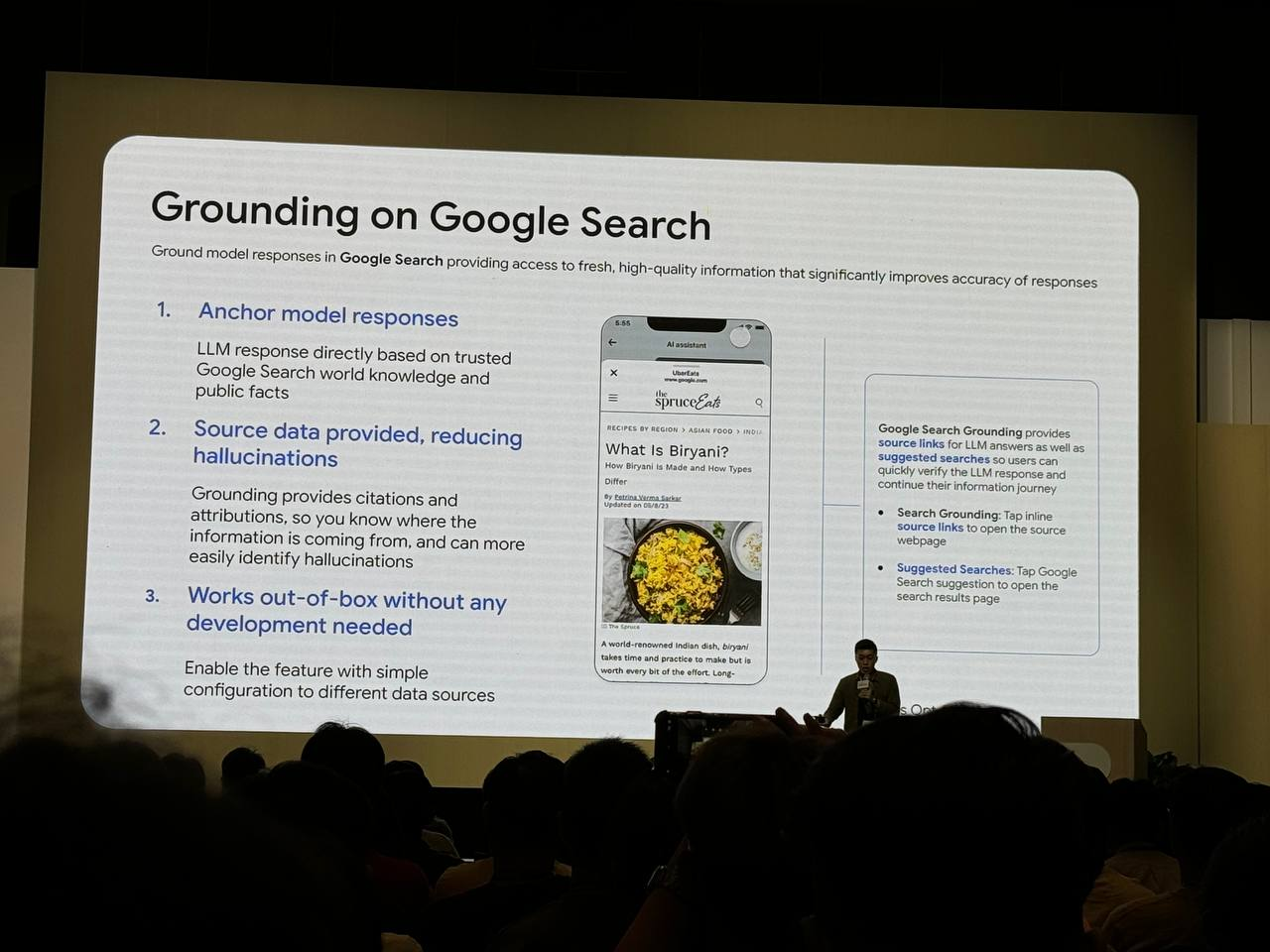
Uber eat的食物介紹根據 Google Search Grounding 提供可靠的資料來源和建議搜尋,提升 LLM 回應的準確性。
當使用者提出查詢時,系統可以利用向量資料庫來儲存和檢索相關資訊。LLM 可以透過 Function Calling 來呼叫向量資料庫的 API,從中提取與查詢最相關的資訊。接著,LLM 可以使用 ranking API 對搜尋結果進行排序,確保最相關的結果排在最前面。

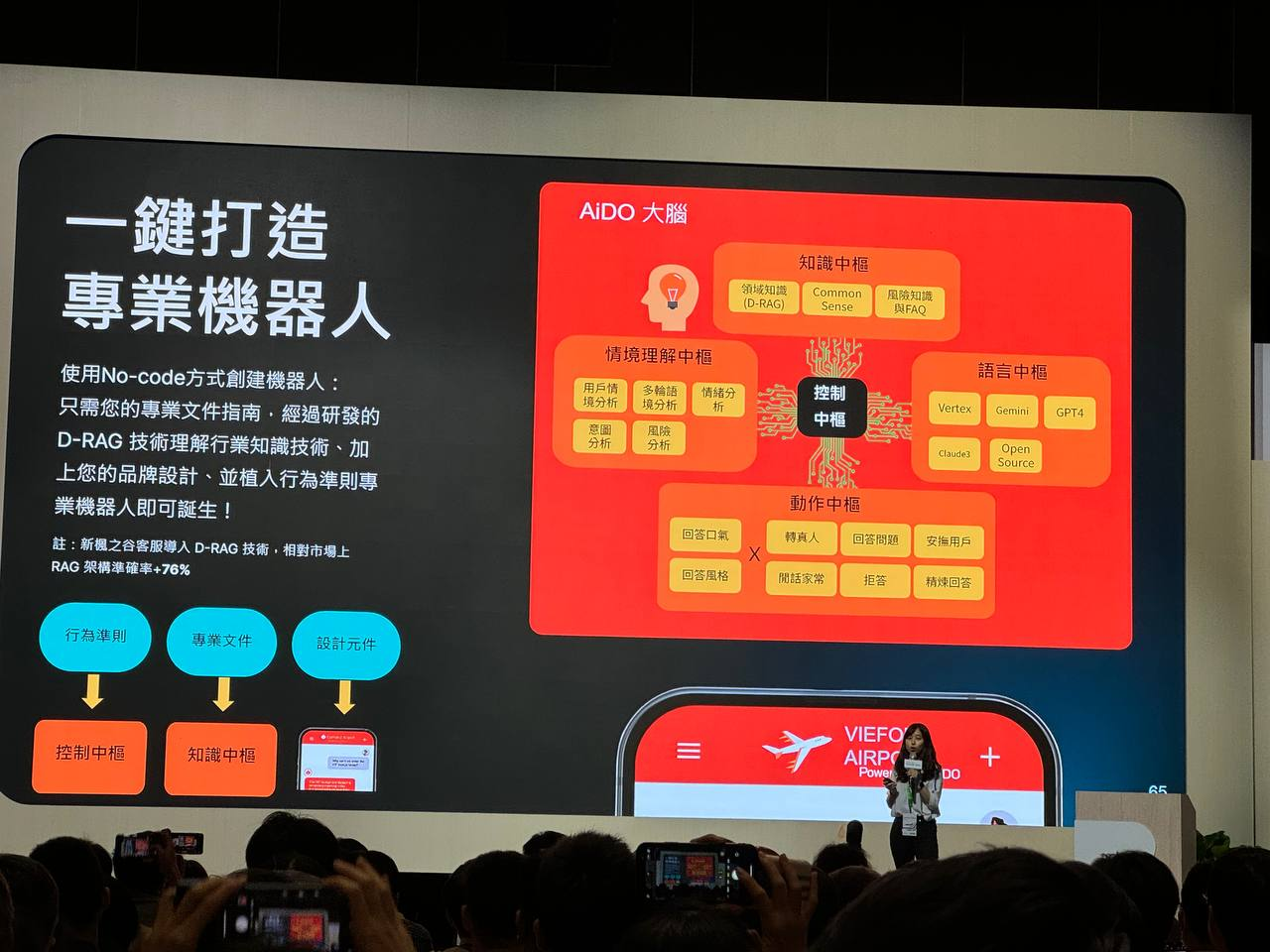
AIDO 打造專業機器人(新楓之谷 遊戲橘子)
AIDO 專業機器人系統的架構和 D-RAG 技術的應用。D-RAG 技術能有效理解行業知識,提升機器人的準確率,並結合其他技術,實現多種功能,如回答問題、安撫用戶、閒話家常等。
使用 No-code 方式創建機器人:使用者只需提供專業文件指南,即可透過 D-RAG 技術創建機器人。
D-RAG
它被用來理解行業知識,並結合品牌設計和行為準則,創造出專業的機器人。根據圖片中的資訊,D-RAG 技術相較於市場上的 RAG 架構,準確率提升了 76%。
AIDO 大腦
AIDO 大腦是這個專業機器人的核心,包含以下幾個中樞:
- 知識中樞:儲存領域知識 (D-RAG)、常識 (Common Sense)、風險知識 (FAO)。
- 情境理解中樞:分析用戶情境。
- 語言中樞:進行多輪語境分析、情緒分析、控制。
- 動作中樞:負責回答問題、安撫用戶、閒話家常、拒絕、精煉回答等。
- 控制中樞:協調各個中樞的運作。
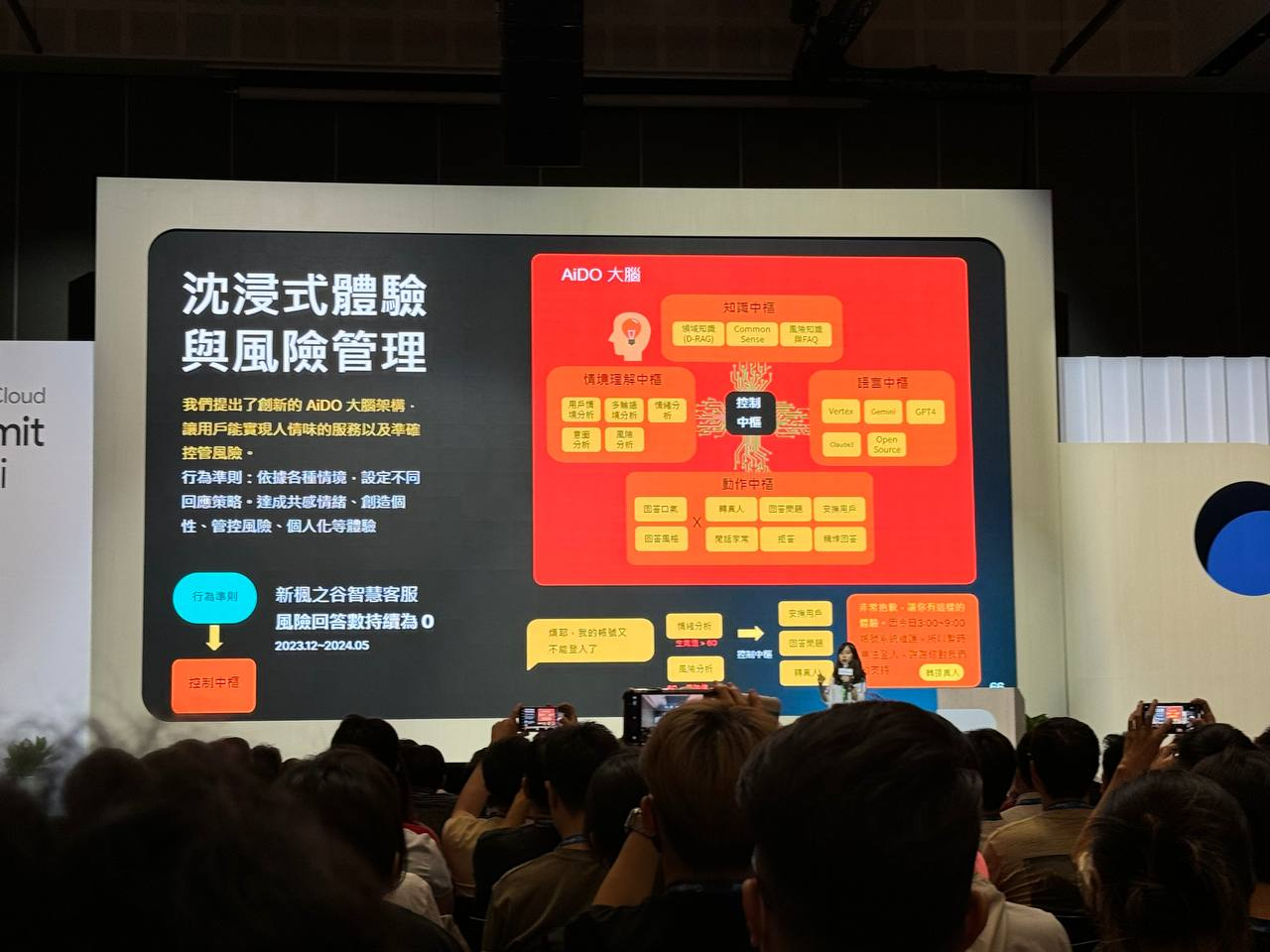
沈浸式體驗與風險管理
AIDO 大腦旨在讓用戶能在與 AI 互動時獲得更人性化的服務,同時也能準確地控管風險。
- 行為準則:AIDO 會根據不同的情境設定不同的回應策略,以達成共情、創造個性、管控風險、個人化等體驗目標。
- 風險回答數持續為 0:這表明 AIDO 大腦在風險管理方面表現出色。
情境理解
AIDO 大腦會分析用戶當下的情境,包括:
- 情緒:用戶的情緒狀態,例如開心、憤怒、悲傷等。
- 意圖:用戶的目的或需求,例如尋求幫助、表達不滿、閒聊等。
- 對話主題:用戶正在談論的話題。
- 用戶資料:用戶的個人資料,例如年齡、性別、興趣等。
行為準則
根據對情境的理解,AIDO 大腦會制定相應的行為準則,包括:
- 共情:對用戶的情緒表示理解和關心。
- 創造個性:展現獨特的個性,讓互動更有趣。
- 管控風險:避免冒犯或傷害用戶,確保對話安全。
- 個人化:根據用戶的資料和偏好,提供個性化的回應。
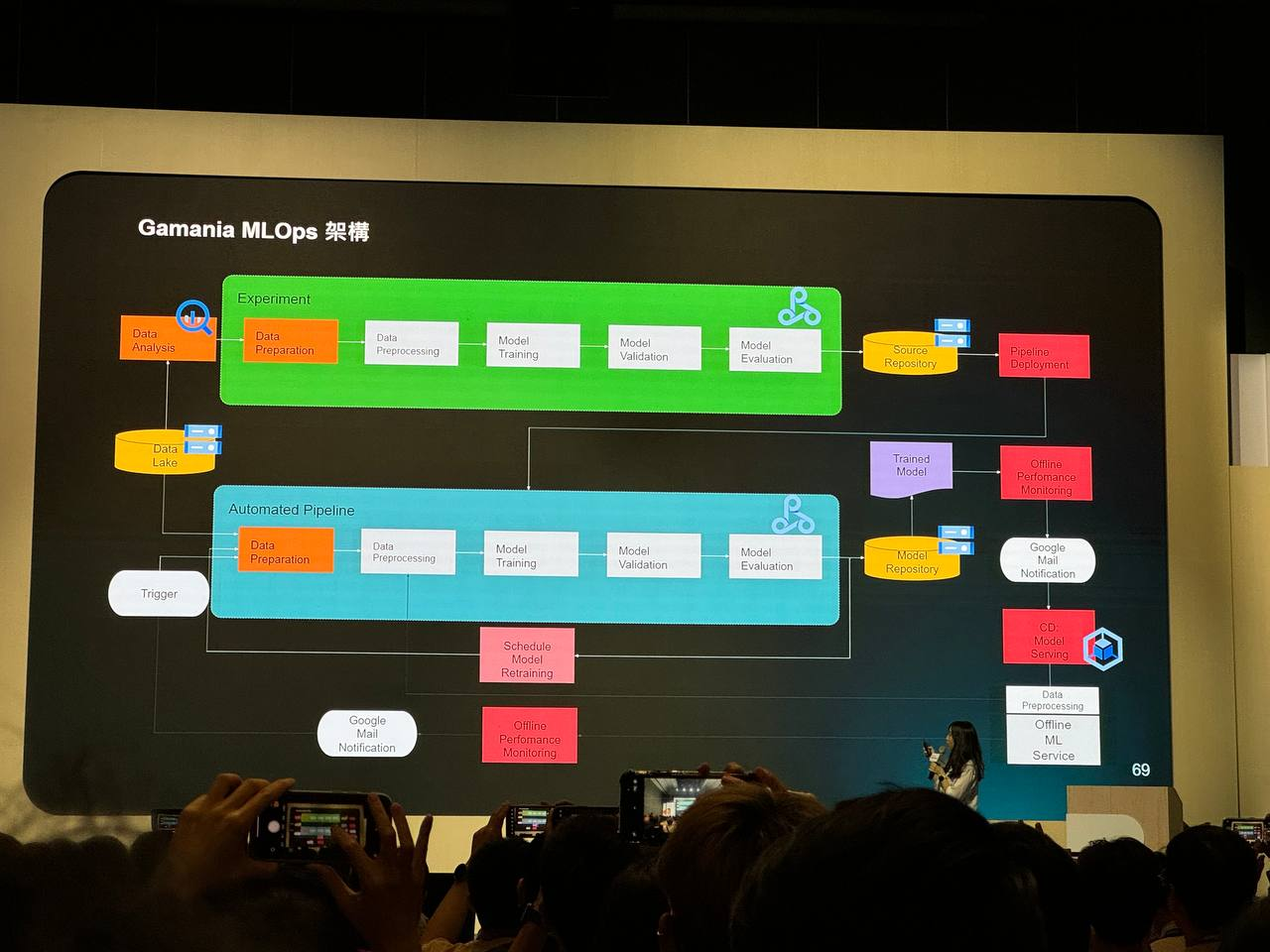
Gamania MLOps 的機器學習運維架構
Gamania MLOps 架構包含了資料分析、資料準備、資料預處理、模型訓練、驗證、評估、部署、監控等環節。這些環節構成了機器學習模型從開發到部署的完整生命週期。
自動化流程
Gamania MLOps 架構強調自動化,這意味著許多任務,例如資料準備、預處理、模型訓練和評估,都可以自動執行。自動化可以提高效率,減少人為錯誤,並確保模型的持續更新。
模型部署與監控
一旦模型經過訓練和驗證,就會被部署到生產環境中。部署後,系統會持續監控模型的表現,並根據需要進行重新訓練。這種持續監控和改進的機制確保模型能夠適應不斷變化的數據和環境。
如何自動加入正確答案到資料庫
雖然圖片中沒有明確顯示如何將正確答案自動加入資料庫,但我們可以推測以下幾種可能性:
- 人工標註:在模型訓練過程中,可能需要人工標註一些數據,這些標註數據可以作為正確答案加入資料庫。
- 模型預測:模型在部署後,可以對新的數據進行預測,如果預測結果達到一定的準確度,就可以將其作為正確答案加入資料庫。
- 回饋機制:系統可以收集用戶對模型回答的回饋,如果用戶認為回答正確,就可以將其加入資料庫。
Gamania MLOps 架構提供了一個自動化的機器學習模型開發、部署和監控的流程。雖然圖片中沒有明確顯示如何自動加入正確答案到資料庫,但可以推測,這可能是透過人工標註、模型預測或用戶回饋等方式實現的。
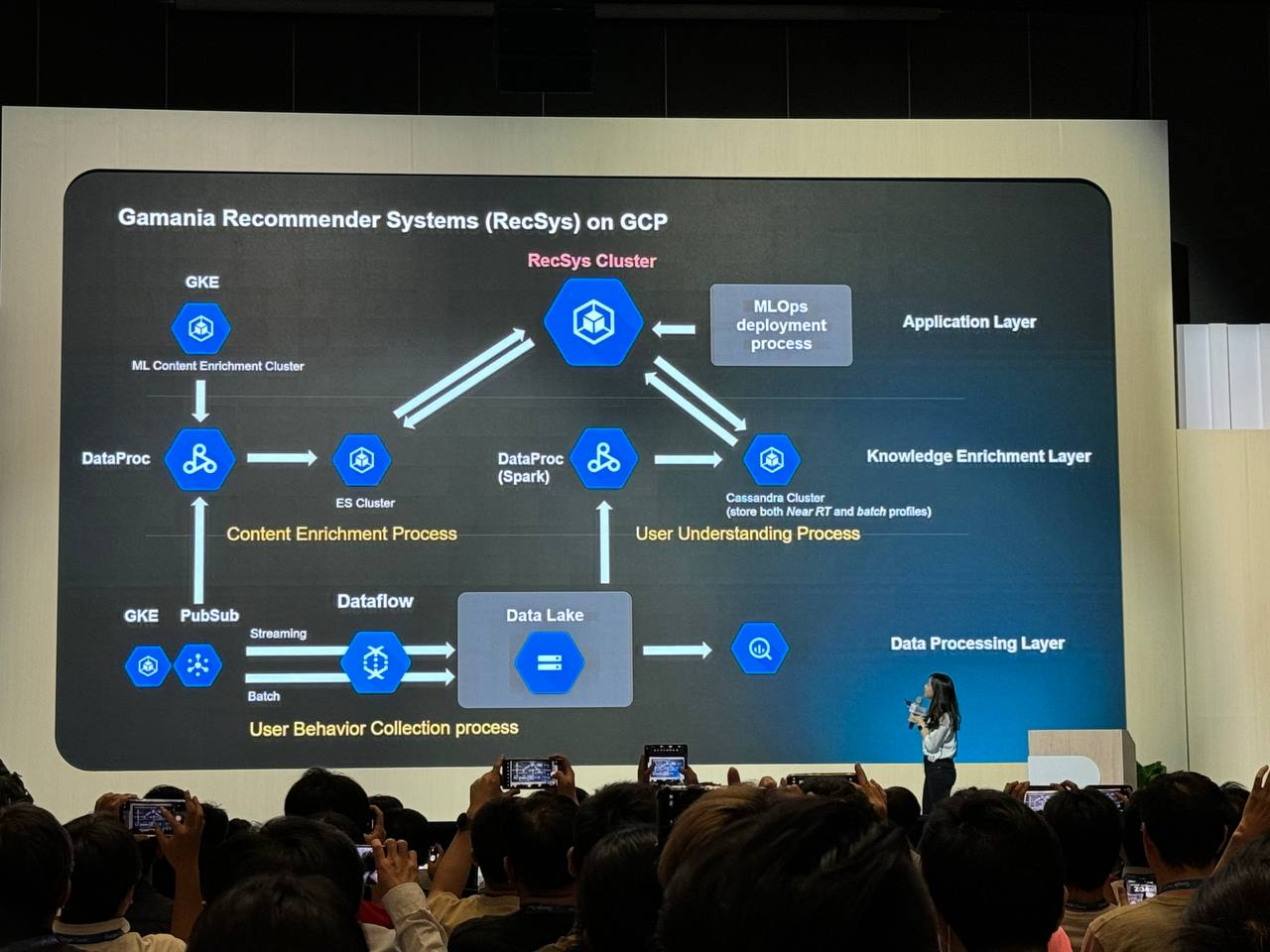
推薦系統架構
Gamania 的推薦系統架構分為三個主要層次:
- 應用層 (Application Layer):負責處理推薦請求,並將結果返回給用戶。其中包含了 MLOps deployment process,表示推薦模型的部署和更新流程。
- 知識增強層 (Knowledge Enrichment Layer):負責處理和豐富內容數據,為推薦系統提供更豐富的資訊。
- 資料處理層 (Data Processing Layer):負責收集、處理和儲存用戶行為數據,為推薦模型提供訓練數據。
各層次組件
- 應用層:
- GKE (Google Kubernetes Engine):用於部署和管理推薦系統的容器化應用。
- 知識增強層:
- DataProc (Spark):使用 Spark 進行批次資料處理,例如內容特徵提取和分析。
- ES Cluster (Elasticsearch Cluster):用於儲存和檢索近乎即時的用戶資料和內容特徵。
- Cassandra Cluster:用於儲存批次處理後的用戶資料和內容特徵。
- 資料處理層:
- GKE:用於部署和管理資料收集和處理的容器化應用。
- PubSub (Google Cloud Pub/Sub):用於傳遞用戶行為事件。
- Dataflow (Google Cloud Dataflow):用於即時處理用戶行為數據。
- Data Lake:用於儲存原始和處理後的用戶行為數據。
資料流程
- 用戶行為收集:GKE 上的應用收集用戶行為數據,並透過 PubSub 傳遞。
- 即時資料處理:Dataflow 處理 PubSub 中的用戶行為事件,並將結果儲存到 Data Lake 和 ES Cluster。
- 批次資料處理:DataProc (Spark) 處理 Data Lake 中的用戶行為數據,並將結果儲存到 Data Lake 和 Cassandra Cluster。
- 內容豐富化:DataProc (Spark) 處理外部內容數據,並將結果儲存到 ES Cluster 和 Cassandra Cluster。
- 推薦生成:GKE 上的推薦系統應用根據用戶資料、內容特徵和推薦模型生成推薦結果。
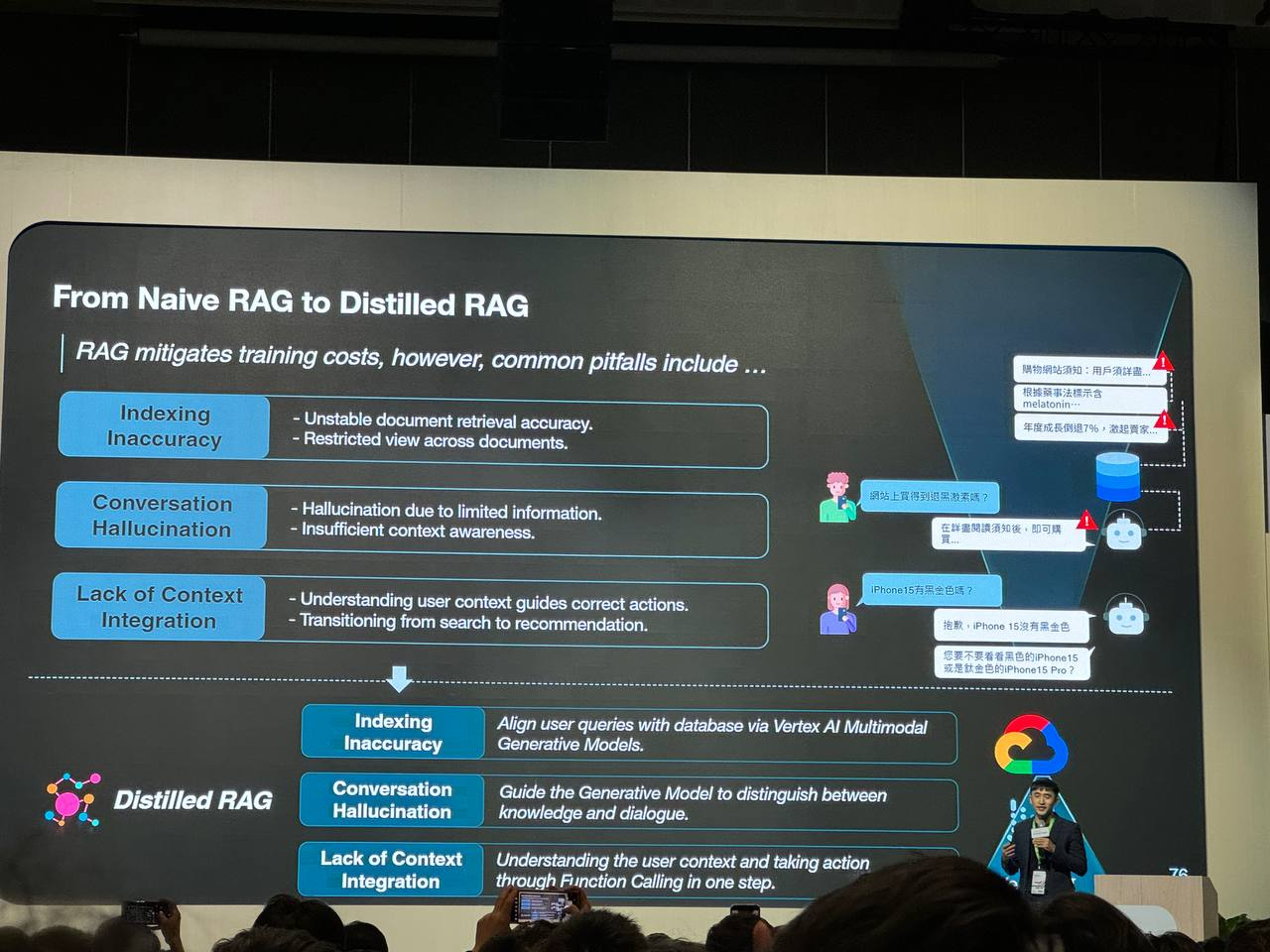
如何解決 RAG 在時效性、幻覺和上下文整合方面
Distilled RAG 在 Naive RAG 的基礎上,透過更精確的索引、更好的上下文理解和更靈活的行動能力,有效解決了時效性、幻覺和上下文整合的問題,從而提供更準確、更相關、更符合用戶需求的回應。
Naive RAG 的問題
- 索引不準確性 (Indexing Inaccuracy):文件檢索的準確性不穩定,即使給定了正確的資料,仍可能出現幻覺,即生成不準確或無意義的回應。
- 對話幻覺 (Conversation Hallucination):由於資訊有限,模型容易產生幻覺,無法理解用戶的上下文,導致回應不符合預期。
- 缺乏上下文整合 (Lack of Context Integration):模型無法充分理解用戶的上下文,難以在搜尋和推薦之間做出適當的轉換。
Distilled RAG 的解決方案
Distilled RAG 透過以下方式解決上述問題:
- 索引不準確性:利用 Vertex AI Multimodal Generative Models 來比對用戶查詢和資料庫,提高檢索的準確性。
- 對話幻覺:引導生成模型區分知識和對話,減少幻覺的產生。
- 缺乏上下文整合:透過 Function Calling,一步到位地理解用戶上下文並採取行動,例如在適當的時候從搜尋切換到推薦。
資訊檢索不準確問題
Distilled RAG 相較於 Naive RAG,透過更先進的模型、更精確的匹配演算法和資料擴增技術,有效解決了資訊遺漏和查詢與文件不匹配的問題,從而提供更準確、更相關的檢索結果。
Naive RAG 的問題
Naive RAG 主要面臨兩個問題:
- 資訊遺漏 (Information Loss):在將文件分割成固定長度的區塊時,可能會遺漏關鍵資訊,導致檢索結果不準確。
- 查詢和文件不匹配 (Query and Document Mismatch):用戶的查詢和文件中的內容可能存在語義上的差異,導致檢索結果不相關。
Distilled RAG 的解決方案
Distilled RAG 透過以下方式解決上述問題:
- Gemini Pro:使用 Gemini Pro 模型來更好地理解用戶查詢和文件內容,從而提高檢索的準確性。
- Vertex AI Matching Engine:將用戶查詢和資料庫文件轉換為向量表示,並透過比對向量來尋找最相似的文件,進一步提高檢索的準確性。
- 資料擴增 (Data Augmentation):透過語言模型生成多種不同表述方式的查詢,擴大搜尋範圍,提高檢索的召回率。

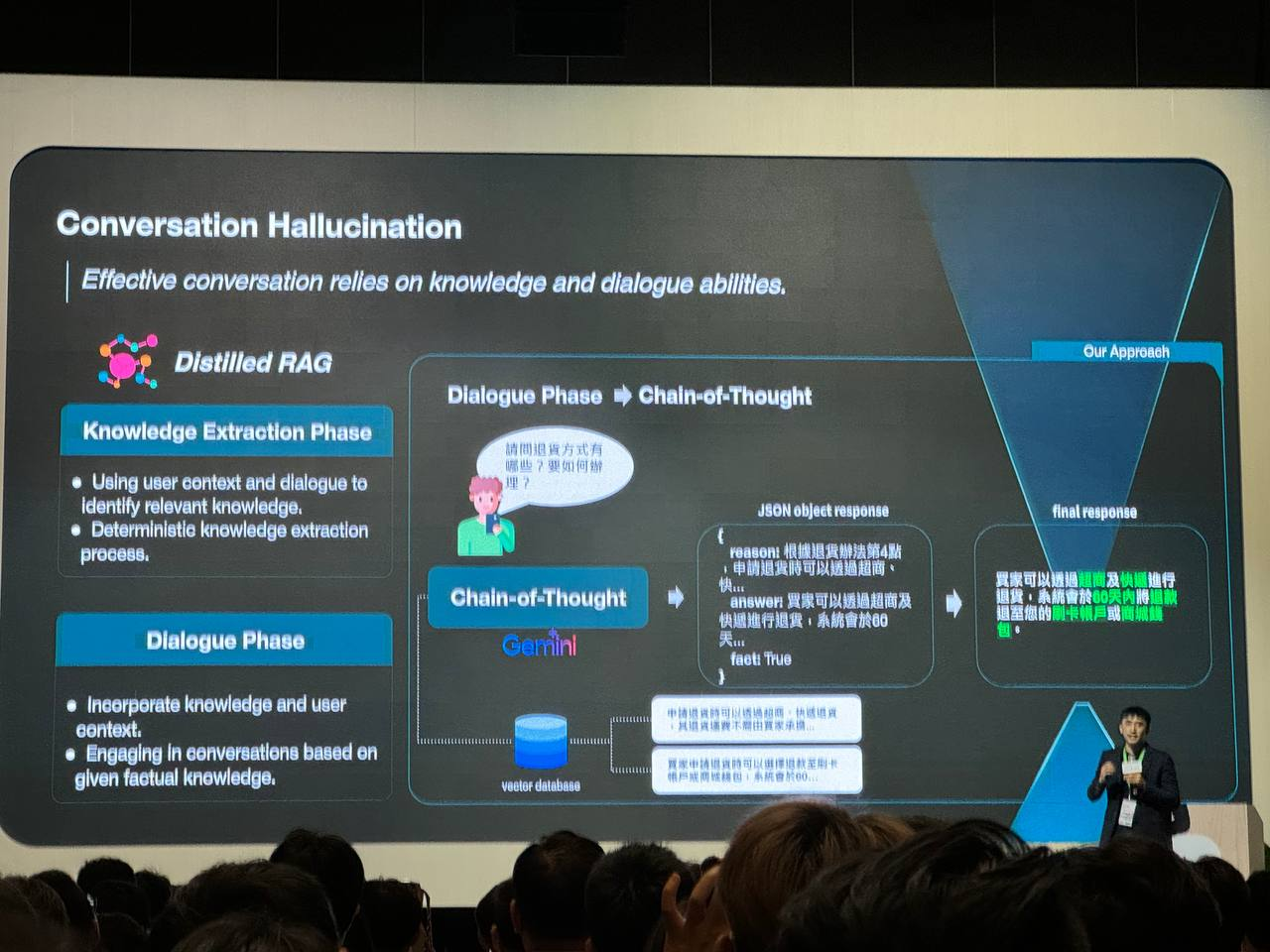
對話幻覺
Distilled RAG 透過將知識提取和對話生成分開,並引入鏈式思考的機制,有效降低了對話式 AI 中的幻覺問題。這種方法確保模型的回答基於可靠的知識,同時也能夠理解和回應用戶的上下文。
對話幻覺 (Conversation Hallucination)
- 問題:對話式 AI 在生成回應時,可能會受到先前對話內容的干擾,導致產生不準確或不相關的回答,這種現象稱為「幻覺」。
- 原因:模型在學習和查詢階段的混雜,使得模型無法區分哪些資訊是來自知識庫,哪些是來自先前的對話。
Distilled RAG 的解決方案
Distilled RAG 將對話過程分為兩個階段,以降低幻覺的產生:
- 知識提取階段 (Knowledge Extraction Phase):
- 使用用戶上下文和對話來識別相關知識:模型會分析用戶的查詢和對話歷史,從向量資料庫中檢索最相關的知識。
- 確定性的知識提取過程:透過一個明確的流程來提取知識,確保提取的知識是準確可靠的。
- 對話階段 (Dialogue Phase):
- 鏈式思考 (Chain-of-Thought):模型會逐步思考,將提取的知識與用戶上下文結合,生成更準確、更符合邏輯的回答。
- 基於事實知識進行對話:模型的回答會基於提取的事實知識,避免受到先前對話內容的干擾。
Function Calling 和 Context Detection
Vertex AI Conversation
這個平台旨在讓開發者能輕鬆構建自然且安全的生成式 AI 應用程式。它整合了 Google 的基礎模型和 Search Grounding 功能,並提供可擴展的基礎架構。
Function Calling
Function Calling 是一種讓 AI 模型能夠與外部系統互動的機制。在這個平台中,Function Calling 被用來:
- 理解用戶意圖 (Intention):透過分析用戶的輸入,判斷用戶是想查詢資訊、尋求幫助,還是表達情感。
- 偵測用戶情境 (Context):了解用戶當前的狀態,例如情緒、對話主題、使用設備等。
- 辨識對話主體 (Subject):確定用戶正在談論的主題或物件。
Context Detection
Context Detection 是指 AI 模型能夠根據上下文資訊來調整其回應。在這個平台中,Context Detection 被用來:
- 判斷是否需要轉接真人客服:如果用戶的情緒激動或問題複雜,系統可以自動將對話轉接給真人客服。
- 提供更個人化的回應:根據用戶的意圖、情境和主體,系統可以提供更符合用戶需求的回應。
BigQuery AI資料分析技術
BigQuery Studio
BigQuery Studio 能够直接在 BigQuery 中執行計算任務,無需額外設置和管理伺服器資源,從而簡化了資料處理流程,提高了效率。
BigQuery Data Canvas
使用者可以透過自然語言與 BigQuery Data Canvas 互動,無需編寫複雜的 SQL 語法,即可探索和分析資料。
在生成 SQL 語法後,使用者可以確認語法的正確性,然後直接在 BigQuery Data Canvas 中執行。
BigQuery Continuous SQL
BigQuery Continuous SQL 是一種在 BigQuery 中處理串流資料的功能。它允許您定義 SQL 查詢,這些查詢會持續監聽 Cloud Pub/Sub 中的訊息,並在訊息到達時立即執行。
這種架構可以用於各種即時文字生成的應用場景,例如:
- 個人化廣告:根據用戶的實時位置或行為生成個性化的廣告。
- 聊天機器人:根據用戶的輸入生成自然的回應。
- 內容摘要:自動生成文章或新聞的摘要。
BigQuery ML & Generative AI Pipelines
這個流程結合了機器學習模型 (BQML Models)、生成式 AI 模型 (LLMs) 和 Vertex AI Pipelines,將圖片和文字資料轉換為有用的資訊,並應用於各種場景。
圖片處理
- Vision AI API:
- 圖片分類 (Image Classification):將圖片分門別類,例如識別產品類型、缺陷等。
- 物件偵測 (Object Detection):在圖片中定位並識別特定物件,例如貨架上的商品、生產線上的零件等。
- 視覺問答 (Visual Q&A):根據圖片內容回答問題,例如「這張圖片中有多少個蘋果?」
- 多模態嵌入生成 (Multimodal embedding generation):將圖片和文字轉換為向量表示,方便後續的相似度比對和分析。
文字處理
- Natural Language API:
- 情感分析 (Sentiment Analysis):分析文字的情感傾向,例如正面、負面或中性。
- 實體抽取 (Entity Extraction):從文字中提取關鍵資訊,例如產品名稱、品牌、規格等。
- 語法分析 (Syntax Analysis):分析句子的結構和文法。
- 文字嵌入生成 (Text embedding generation):將文字轉換為向量表示。
- 機器翻譯 (Machine Translation):將文字翻譯成其他語言。
- LLMs:
- 內容生成 (Content generation):根據輸入的提示生成文字,例如產品描述、廣告文案等。
- 摘要 (Summarization):自動生成文章或文件的摘要。
- 改述 (Rephrasing):用不同的方式表達相同的內容。
向量資料庫
向量資料庫用於儲存圖片和文字的向量表示,並支援向量特徵的比對。這使得我們可以透過向量相似度來尋找相似的圖片或文字。
應用場景
- 零售業:
- 圖片搜尋:根據圖片內容搜尋相似的商品。
- 自動標記:自動為商品圖片生成標籤和描述。
- 視覺問答:讓顧客透過圖片詢問商品資訊。
- 製造業:
- 缺陷檢測:自動檢測產品圖片中的缺陷。
- 庫存管理:透過圖片識別和分類來管理庫存。
- 自動報告生成:根據生產線上的圖片生成生產報告。

活動官網: